🖋Haskell String Types
The goal of this blog post is to ease the confusion of Haskell string types. I assume you already know what String is, so I’ll only cover the difference between types and help to build intuition on what type you should choose for the task in hand.
Note: It’s a second edition of the blog post. You can find the first one on GitHub
String
As you all know, String is just a type synonym for list of Chars:
type String = [Char]
That is good because you can use all functions for list manipulations on Strings. The bad news is that storing such strings implies massive overhead, up to 4 words per character and size of Char itself is 2 words. This also affects speed.
To see why overhead is so high, check slide 43 from Johan Tibell’s High-Performance Haskell presentation:
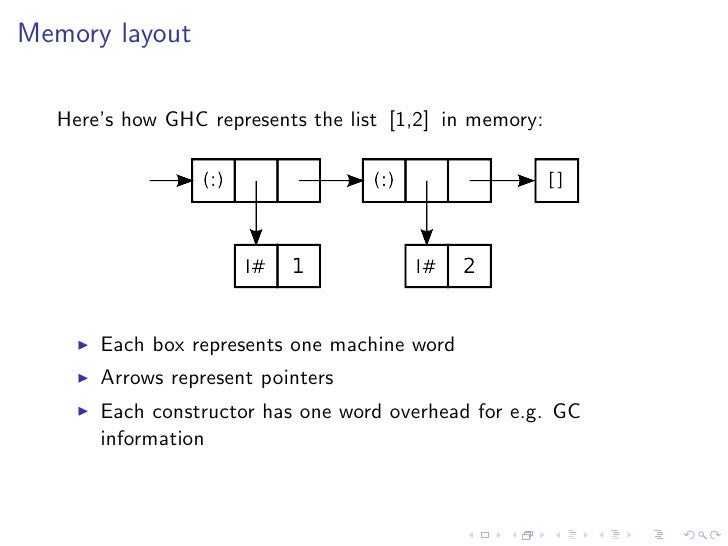
That’s why we have Text.
Text
text package provides an efficient packed Unicode text type. Internally, the Text type is represented as an array of Word16 UTF-16 code units. The overhead for storing a string is 6 words.
To convert between String and Text you can use pack and unpack from Data.Text module.
The Data.Text module also provides many functions to work with Text and mimics the list interface. It also provides a full-string case conversion functions (map toUpper doesn’t work for Unicode because the result could have a different length). The module is intended to be imported qualified. There are also I/O functions in Data.Text.IO module.
The downside of storing the string in a strict array is that way it forces the whole string to be in memory at the same time, which negates lazy I/O (when you call readFile, it reads the whole file in the memory before starting processing). That’s why the library provides the second string type: Data.Text.Lazy.Text. It uses a lazy list of strict chunks, so this type is suitable for I/O streaming.
You can think of lazy Text as [Data.Text.Text]. In fact, there are toChunks and fromChunks functions that convert lazy Text to/from a list of strict Text.
The Data.Text.Lazy module copies the interface of Data.Text module but for lazy Text. To convert between strict and lazy Text, use toStrict and fromStrict functions.
ByteString
There is also a type you will see often called ByteString. The funny thing is that it’s not intended to be a string. The ByteString type is an array of bytes that comes in both strict and lazy forms; it’s great for serialization and passing data between C and Haskell. It may be a bit faster than Text for some operations because Text does more work to handle Unicode properly.
Generally, you shouldn’t use this type for text manipulation as it doesn’t support Unicode. But you should know how to deal with =ByteString=s because it’s de facto standard type for networking, serialization, and parsing in Haskell.
The standard view into ByteString types represent elements as Word8. Data.ByteString and Data.ByteString.Lazy modules provide functions that mimic [Word8] interface.
It’s also possible to treat bytes as characters. Data.ByteString.Char8 and Data.ByteString.Lazy.Char8 modules re-export the same bytestring types (so you don’t need to convert between Data.ByteString.ByteString and Data.ByteString.Char8.ByteString types) and provide functions to see ByteString as a list of =Char=s.
But you should be cautious because truncating is possible. For example, calling pack on Unicode strings will truncate character codes and you definitely don’t want this. You should use fromString and toString functions from the utf8-string module instead.
Prelude> import qualified Data.ByteString.Char8 as BS
Prelude BS> import qualified Data.ByteString.UTF8 as BU
Prelude BS BU> BS.putStrLn (BS.pack "hello")
hello
Prelude BS BU> BS.putStrLn (BS.pack "привет")
?@825B
Prelude BS BU> BS.putStrLn (BU.fromString "привет")
привет
Prelude BS BU> putStrLn (BS.unpack (BU.fromString "привет"))
пÑивеÑ
Prelude BS BU> putStrLn (BU.toString (BU.fromString "привет"))
привет
The Data.Text.Encoding module provides functions for encoding/decoding Text to ByteString.
OverloadedStrings
You may often need to create string literals of different types. One possible solution is to use functions to convert String literal to the type you need. For example:
Prelude> import qualified Data.Text as T
Prelude T> T.pack "hello"
"hello"
But that’s really tiresome to type all these conversion functions all over again, especially when the number of strings in the code is high.
The other possible solution is to enable OverloadedStrings language pragma. You can place {-# LANGUAGE OverloadedStrings #-} in your source code to start.
Let’s check what it does in ghci:
Prelude> :t "hello"
"hello" :: [Char]
Prelude> :set -XOverloadedStrings
Prelude> :t "hello"
"hello" :: Data.String.IsString a => a
As you see, this changes the type of string literals to Data.String.IsString a => a.
The definition of IsString typeclass is simple:
class IsString a where
fromString :: String -> a
fromString defines a function to convert String to the given type. What OverloadedStrings really does is replaces "hello" with fromString "hello". There are instances of IsString for all string types we just covered, so you can use usual "hello" as if it was a bytestring or a text.
Prelude> import qualified Data.ByteString.Char8 as BS
Prelude BS> import qualified Data.Text.IO as T
Prelude BS T> :set -XOverloadedStrings
Prelude BS T> putStrLn "hello"
hello
Prelude BS T> BS.putStrLn "hello"
hello
Prelude BS T> T.putStrLn "hello"
hello
Conclusion
Choose String when you don’t care about performance or strings are small (e.g. identifiers).
Choose Text for general text processing.
Choose ByteString for storing raw bytes, serialization or parsing.
That’s basically all you should know to start working with strings.
Further reading
textlibrary;text-iculibrary for more Unicode features, encodings, normalization and regular expressions;bytestringlibrary;utf8-stringlibrary;ListLikepackage for a common interface to all strings.