👨🔬Alpha #6: Compiling with Continuations, continued
Well, I have programmed myself into a corner, haha 😬. In the previous post, I’ve mentioned that there are several differences between Appel’s representation and what I am trying to do. Turned out, there are too many differences for me to handle on my own, so I have resorted to reading papers. Today, I’ll outline the significant differences and then briefly summarize the papers I’ve read and the great CPS debate.
Differences from Appel’s representation
Appel’s CPS is untyped.
While the source language (Standard ML = SML) is strongly typed, Appel’s CPS IR is not. The only compound value available in the CPS is
RECORD—an arbitrary-width untyped record. Each field of a record can be either a pointer or an unboxed primitive type.Values smaller than 256 (small integers, booleans, constructor variants) are stored unboxed. This requires runtime checks to determine whether a value is boxed or not. This adds a performance penalty to both user program and garbage collector.
Alpha is different. Because the language is dynamically-typed, the runtime type information is preserved for every object. Every boxed object has a type tag that describes the object layout (including the positions of every pointer in the object). This information is used during garbage collection and is also used to determine whether a local variable should be a GC root.
This eliminates the cost of runtime boxing checks, but the compiler now needs to preserve and forward type information. This means my CPS IR should have types.
Type information also helps generate better LLVM IR code as LLVM has types, too.
Multi-method dispatch.
SML does not have any dynamic dispatch mechanism—all functions calls are resolved at compile time. Functions can be represented as either raw function pointers (for known functions) or closures (a record of function pointer + captured variables, for unknown/escaping functions).
In Appel’s CPS, there is no difference between user functions and continuations—both are handled as functions, both can be either raw function pointers or closures.
Alpha complicates the matters with multi-methods. Functions in Alpha can have multiple implementations (methods) associated, and the appropriate one is selected at runtime (for now) based on the values of arguments.
That means that Alpha’s closure format is more involved. If Appel’s closure is just a record with a function pointer and captured variables, Alpha needs to allocate a type descriptor, and the method is attached to the type (these are one-time actions). A closure is an object with that type tag, and fields are captured variables.
Furthermore, not all arguments are equal. CPS translation adds a continuation parameter to every user function, and it does not participate in Alpha’s method resolution—only user-defined parameters do.
And the cherry on top: continuations have a different signature—they don’t have a continuation parameter.
type UserFn = extern "fastcall" fn(args: *const SVec, k: *const AlphaValue); type ContFn = extern "fastcall" fn(args: *const SVec);The compiler needs to differentiate regular functions and continuations. It is possible to treat them both as functions, but that makes the tracking implicit—and implicit is harder to reason about.
JIT compilation
SML/NJ is a whole-program compiler. This means it takes all source code as input and produces an executable. A compilation unit for SML/NJ is an SML module.
A module is desugared into a record that contains all public functions. The compiler doesn’t have to treat private and public functions differently—it’ll see that public functions are stored into a record (are escaping) and will convert them into closures.
Alpha is more dynamic: top-level expressions are allowed, and their execution is intermixed with compiling other functions. In the future, it would be possible to influence the compiler’s state so that the following functions are compiled (or even parsed) differently. Because of this dynamism, a compilation unit in Alpha is much smaller—it’s one top-level declaration (type, function, or expression).
The main complication is that top-level functions are treated differently. During the closure conversion pass, a nested function always allocates a new function type and attaches a new method to it. However, top-level functions are different because they can attach methods to existing functions—this means that applying closure conversion to top-level functions does the wrong thing as it always allocates a function type.
But top-level functions must be closures, so the closure conversion must occur! I have been thinking about closure-converting top-level functions during AST→CPS lowering. But then generic closure conversion could kick in and double-convert it—which is horribly wrong and won’t work.
CPS or not CPS debate
There is a series of papers discussing whether CPS is a good intermediate representation for a functional language or direct style IR is a better one.
TL;DR: some optimizations are easier to perform in CPS form, and some are easier in direct style. CPS transformation is usually followed by un-CPS transformation, so it should be possible to implement any CPS optimization without the conversion back and forth, and that’s what Administrative-Normal Form (ANF) is doing. Although it suffers from inlining due to re-normalization, and also requires introducing join points to avoid code size blow up (and join points are continuations). Well, it’s complicated… There are many trade-offs, and the latest paper suggests that “CPS or not” shouldn’t be an either-or choice, but rather it should be “as much or as little CPS as you want.”
Compiling with Continuations book (1992) by Andrew W. Appel is the most cited resource on CPS and is usually referenced as the starting point of the debate. (There is also Continuation-passing, closure-passing style paper (1989) by Appel and Jim that can be used as a shorter introduction.) As you might have guessed, it proposes that CPS is an excellent IR for compilers for functional programming languages.
The essence of compiling with continuations paper (1993) by Flanagan et al. argues that any mature CPS-based compiler has an un-CPS pass which undoes the initial CPS transformation. Combined with a series of β-normalizations in between, the whole purpose is to optimize the initial direct style code. Therefore, CPS and un-CPS transformations are potentially unnecessary, and all CPS optimizations could be performed in the direct style (as suggested by the image below).
The authors show how this can be implemented for a small subset of a Scheme and introduce Administrative Normal Form (ANF for short). Although subsequent papers showed that the subset is simplistic and hides some issues with ANF, the paper flamed the CPS debate.
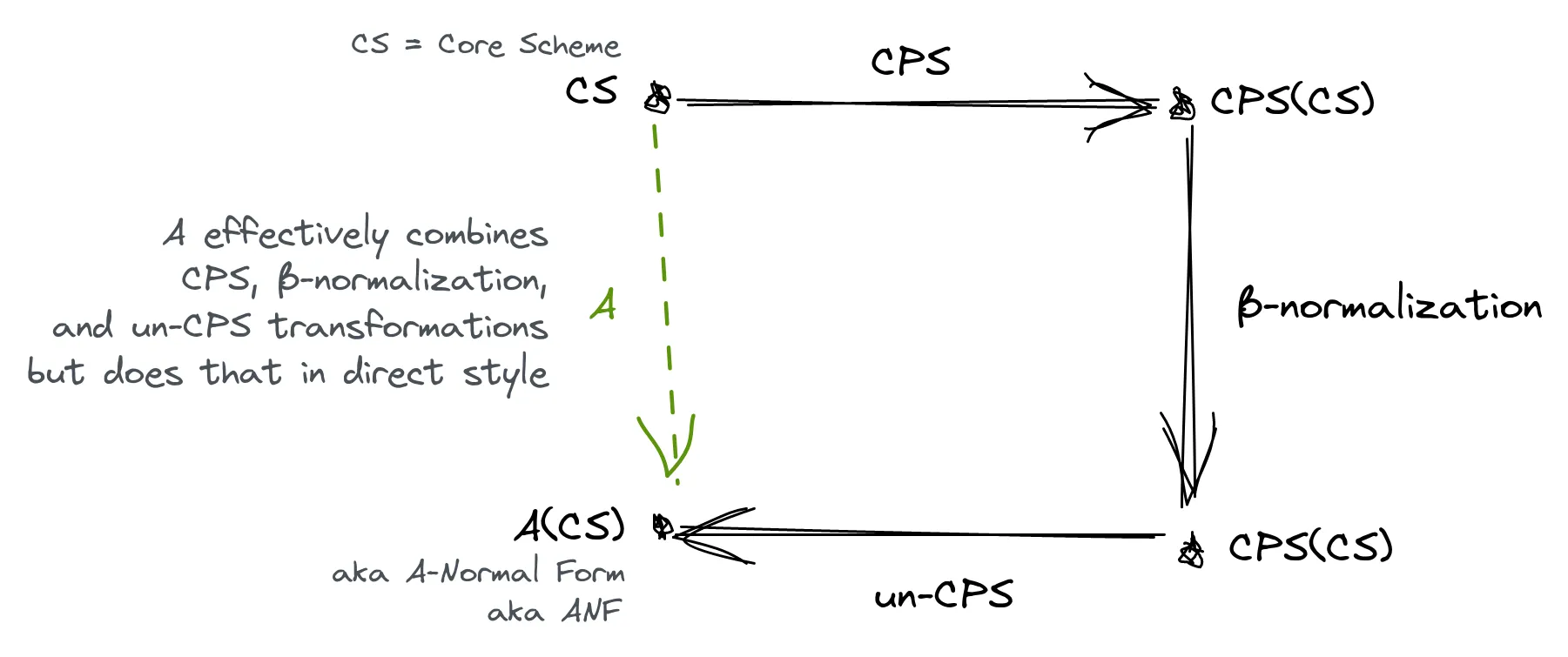
In Compiling with Continuations, Continued (2007), Andrew Kennedy argues back that CPS is still a good form to use: “the language is smaller and more uniform, simplification of terms is more straightforward and extremely efficient, and advanced optimization such as contification are more easily expressed.” He also argues that ANF—even though it avoids CPS and un-CPS transformations—leads to worse performance when inlining because it requires re-normalization (so the inlining is ), and adding conditional expressions to the source language requires introducing join points which are basically continuations (so you might as well use full CPS).
The paper comes from Andrew’s experience implementing the SML.NET compiler and is also packed with practical tips:
- How to stack-allocate all continuations so that CPS compiles down to jumps, function calls, and returns, and continuations become labeled basic blocks.
- How to represent CPS in a graph form (vs. traditional trees), which allows implementing many operations in near-constant time.
- How to add typing information and exceptions (using double-barrelled continuations). This also gives effect analysis for exceptions “for free,” enabling more optimizations.
- How to implement contification—converting user functions to continuations. Because continuations are guaranteed to be stack-allocated, this has the effect of inlining a function without increasing the program size—even if it’s called multiple times.
We use CPS only because it is a good place to do optimization; we are not interested in first-class control in the source language (call/cc), or as a means of implementing other features such as concurrency. […] the compilation process can be summarized as “transform direct style (SML) into CPS; optimize CPS; transform CPS back to direct style (.NET IL)”
If you’re interested in continuations, I highly recommend reading Kennedy’s paper.
Compiling without continuations (2017) by Maurer, Ariola, Downen, and Peyton Jones replies by adding join points as an explicit construct to ANF. (Implemented in Glasgow Haskell Compiler). This way, the compiler can treat them differently and preserve them during optimizations. This brings the power of Kennedy’s representation to ANF but avoids CPS and un-CPS transformations.
The paper also notes other benefits of direct style: it is easier to read and reason about (important because performance-hungry Haskell programmers do read compiler’s IR), and some transformations are easier to implement (especially the ones required for a call-by-need language that Haskell is). And the authors also found that introducing join points has (unexpectedly) resolved a long-standing issue with stream fusion.
It’s worth noting that this representation is very similar to Kennedy’s. The only difference is that’s it is in direct style. It doesn’t produce faster code, and although it avoids CPS and un-CPS transformations, it doesn’t seem to solve the inlining issue. I believe this representation is good for Haskell (call-by-need languages) but is not particularly useful for me.
Compiling with continuations or without? Whatever. (2019) by Cong, Osvald et al. is the latest paper in this series. It tries to “settle the ‘CPS or not CPS’ debate once and for all with a decisive ‘it depends!’” It introduces a new control operator that allows going into CPS selectively, so you can do as much or as little CPS as you want. It allows using both direct style and CPS optimizations—whichever performs better.
We’ll see if this stops the debate, though…
My conclusions
So… this stuck situation seems to be typical of me trying to implement all cool features simultaneously. I should tame my appetite, really.
I’ll go with Kennedy’s representation as I have a good understanding of it, and it solves many of my questions. All continuations will be non-escaping and stack-allocated for now.
As a consequence, implementing async in a way I see it is not possible with this IR. Although I feel that I can fix it later (either by adding continuation-to-function transformation or allocating a stack for each green thread).
For now, I just need to unblock myself and keep going.